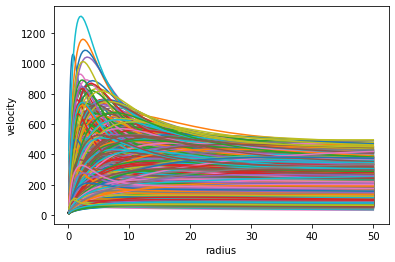
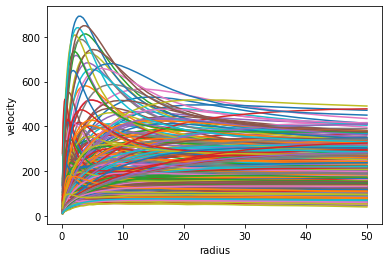
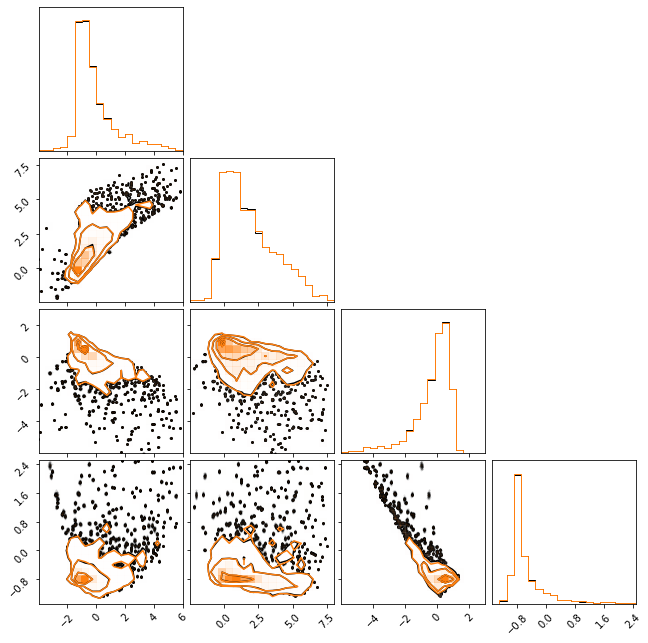
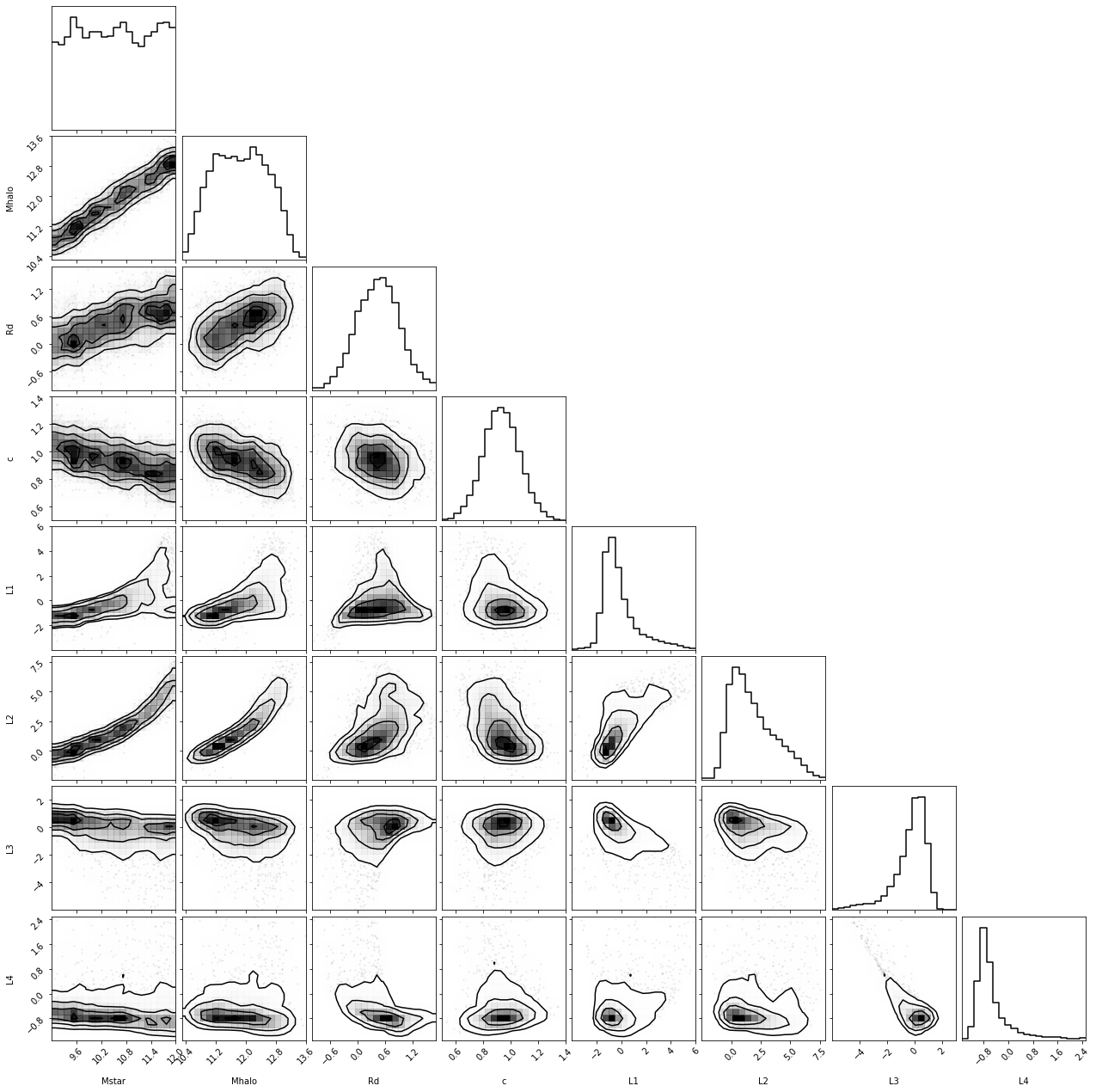
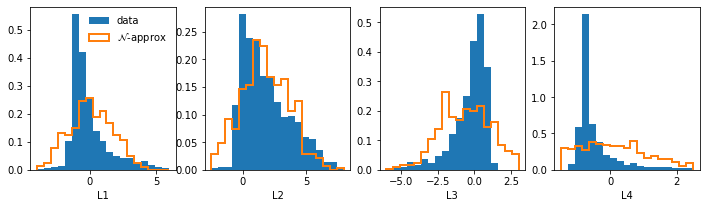
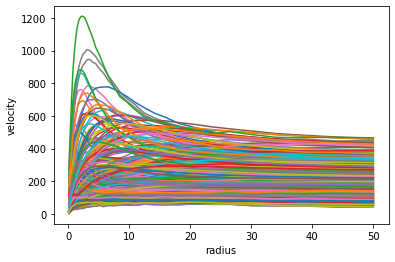
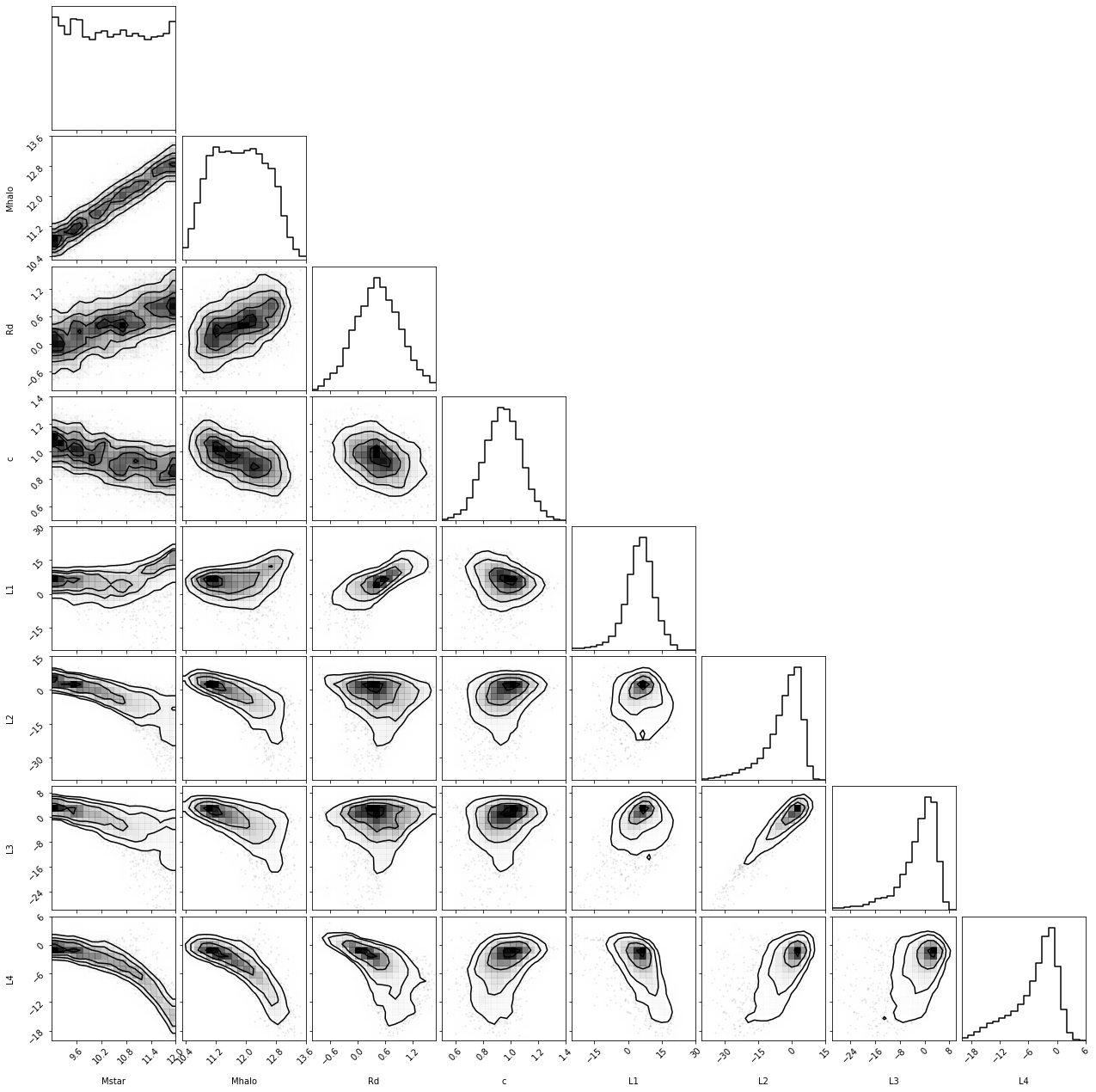
class VariationalAutoEncoder(nn.Module):
def __init__(self, ninp, **kwargs):
super().__init__()
self.encodeLayer1 = nn.Linear(in_features=ninp, out_features=32)
self.encodeLayer2 = nn.Linear(in_features=32, out_features=16)
self.encodeOut = nn.Linear(in_features=16, out_features=14)
self.decodeLayer1 = nn.Linear(in_features=4, out_features=16)
self.decodeLayer2 = nn.Linear(in_features=16, out_features=32)
self.decodeOut = nn.Linear(in_features=32, out_features=ninp)
self.ELBO_loss = None
def encoder(self, x):
mean, logvar, covs = torch.split(self.encodeOut(F.relu(self.encodeLayer2(F.relu(self.encodeLayer1(x))))),
[4, 4, 6], dim=1)
return mean, logvar, covs
def decoder(self, encoded): return self.decodeOut(F.relu(self.decodeLayer2(F.relu(self.decodeLayer1(encoded)))))
def reparametrize(self, mean, m_cov):
eps = tensor(rng.normal(size=mean.shape), dtype=torch.float)
# return eps * var.sqrt() + mean
# find matrix square root with SVD decomposition
# https://math.stackexchange.com/questions/3820169/a-is-a-symmetric-positive-definite-matrix-it-has-square-root-using-svd?noredirect=1&lq=1
U,S,V = torch.svd(m_cov) # A = U diag(S) V.T
dS = torch.stack([torch.diag(S[i,:]) for i in range(S.shape[0])]) # sqrt(A) = U diag(sqrt(S)) V.T
cov_sqrt = torch.einsum('bij,bkj->bik',torch.einsum('bij,bjk->bik',U,dS.sqrt()),V)
return torch.einsum('bij,bi->bj', cov_sqrt, eps) + mean
def _ELBO(self, x, decoded, mean, m_cov, var):
mseloss = nn.MSELoss(reduction='sum')
logpx_z = -mseloss(x, decoded)
KLdiv = -0.5 * (torch.log(m_cov.det()) + 4 - torch.sum(mean**2 + var, dim = 1))
return torch.mean((KLdiv - logpx_z)[~(KLdiv - logpx_z).isnan()]) # torch.nanmean
def _get_m_cov(self, logvar, covs):
# covariance matrix
m_cov = torch.zeros(logvar.shape[0], 4, 4)
m_cov[:,[0,1,2,3],[0,1,2,3]] = logvar.exp()
m_cov[:,[0,0,0,1,1,2],[1,2,3,2,3,3]] = covs
m_cov[:,[1,2,3,2,3,3],[0,0,0,1,1,2]] = covs
# var = torch.einsum('bii->bi', m_cov)
return m_cov, logvar.exp()
def forward(self, x):
mean, logvar, covs = self.encoder(x)
m_cov, var = self._get_m_cov(logvar, covs)
z = self.reparametrize(mean, m_cov)
decoded = self.decoder(z)
self.ELBO_loss = self._ELBO(x, decoded, mean, m_cov, var)
return decoded
def getELBO_loss(self, x):
mean, logvar, covs = self.encoder(x)
m_cov, var = self._get_m_cov(logvar, covs)
z = self.reparametrize(mean, m_cov)
decoded = self.decoder(z)
return self._ELBO(x, decoded, mean, m_cov, var)